Since the time git cherry-pick learned to be able to apply multiple commits, the distinction indeed became somewhat moot, but this is something to be called convergent evolution 😉
The true distinction lies in original intent to create both tools:
-
git rebase‘s task is to forward-port a series of changes a developer has in their private repository, created against version X of some upstream branch, to version Y of that same branch (Y > X). This effectively changes the base of that series of commits, hence “rebasing”.(It also allows the developer to transplant a series of commits onto any arbitrary commit, but this is of less obvious use.)
-
git cherry-pickis for bringing an interesting commit from one line of development to another. A classic example is backporting a security fix made on an unstable development branch to a stable (maintenance) branch, where amergemakes no sense, as it would bring a whole lot of unwanted changes.Since its first appearance,
git cherry-pickhas been able to pick several commits at once, one-by-one.
Hence, possibly the most striking difference between these two commands is how they treat the branch they work on: git cherry-pick usually brings a commit from somewhere else and applies it on top of your current branch, recording a new commit, while git rebase takes your current branch and rewrites a series of its own tip commits in one way or another. Yes, this is a heavily dumbed down description of what git rebase can do, but it’s intentional, to try to make the general idea sink in.
Update to further explain an example of using git rebase being discussed.
Given this situation,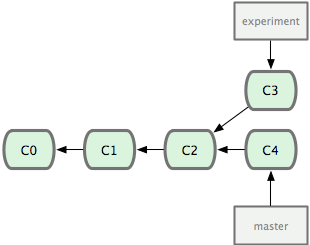
The Book states:
However, there is another way: you can take the patch of the change that was introduced in C3 and reapply it on top of C4. In Git, this is called rebasing. With the rebase command, you can take all the changes that were committed on one branch and apply them onto another one.
In this example, you’d run the following:
$ git checkout experiment $ git rebase master First, rewinding head to replay your work on top of it... Applying: added staged command
“The catch” here is that in this example, the “experiment” branch (the subject for rebasing) was originally forked off the “master” branch, and hence it shares commits C0 through C2 with it — effectively, “experiment” is “master” up to, and including, C2 plus commit C3 on top of it. (This is the simplest possible case; of course, “experiment” could contain several dozens of commits on top of its original base.)
Now git rebase is told to rebase “experiment” onto the current tip of “master”, and git rebase goes like this:
- Runs
git merge-baseto see what’s the last commit shared by both “experiment” and “master” (what’s the point of diversion, in other words). This is C2. - Saves away all the commits made since the diversion point; in our toy example, it’s just C3.
- Rewinds the HEAD (which points to the tip commit of “experiment” before the operation starts to run) to point to the tip of “master” — we’re rebasing onto it.
- Tries to apply each of the saved commits (as if with
git apply) in order. In our toy example it’s just one commit, C3. Let’s say its application will produce a commit C3′. - If all went well, the “experiment” reference is updated to point to the commit resulted from applying the last saved commit (C3′ in our case).
Now back to your question. As you can see, here technically git rebase indeed transplants a series of commits from “experiment” to the tip of “master”, so you can rightfully tell there indeed is “another branch” in the process. But the gist is that the tip commit from “experiment” ended up being the new tip commit in “experiment”, it just changed its base:
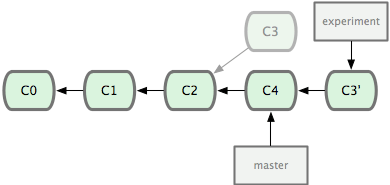
Again, technically you can tell that git rebase here incorporated certain commits from “master”, and this is absolutely correct.